
Share
Amazon MSK
Why Amazon MSK?
MSK (Amazon Managed Streaming for Apache Kafka) is a wholly managed version of Apache Kafka. Amazon MSK will provision your servers, configure your Apache Kafka clusters, replace servers when they fail, etc. With a managed service, you can concentrate your time designing and running streaming event apps rather than worrying about the technical aspects. Apache Kafka clusters are dispersed over multiple Availability Zones (AZs) in Amazon MSK, providing you with resilient and highly available streaming storage. Amazon MSK is an open-source, highly secure Apache Kafka cluster. As Amazon’s highly flexible, observable, and scalable service, Amazon MSK provides the flexibility and control required for a wide range of use cases.
The robust interfaces between Amazon MSK and other AWS services make application development easier with Amazon MSK. It interfaces with AWS Identity and Access Management (IAM), AWS Certificate Manager, Amazon Glue Schema Registry for schema governance, Amazon Kinesis Data Analytics, Amazon Lambda for stream processing, and many more services. Modern messaging and event-driven applications, data input and processing services, and microservice application designs are made possible by Amazon MSK, which serves as the integration backbone for these applications.
How it Works
Amazon MSK makes it simple to ingest and handle streaming data in real-time using Apache Kafka, which Amazon fully manages.

Image sourced from Amazon Web Services
Features
- Executed flawlessly
If you want to deploy Apache Kafka to follow best practices, you can do it with a few clicks in the console or design your cluster from scratch. It’s easy to set up Apache Kafka and ZooKeeper clusters with Amazon MSK.
- Includes Apache ZooKeeper
Apache ZooKeeper is needed to run Apache Kafka, coordinate cluster tasks, and preserve the status of resources that interact with the cluster. Your Apache ZooKeeper nodes will be taken care of by Amazon MSK for you. Each Amazon MSK cluster offers the required number of Apache ZooKeeper nodes for your Apache Kafka cluster at no additional charge.
- MSK Serverless is a service provided by Amazon (Preview)
MSK Serverless is a cluster type for Amazon MSK that makes it simple for you to run Apache Kafka clusters without controlling the capacity of your CPU and storage resources. MSK Serverless manages Apache Kafka partitions while automatically providing and scaling resources, so you don’t have to worry about cluster sizing or scalability when streaming data.
- High availability is the default.
Amazon MSK’s service-level agreement (not applicable to MSK Serverless while in preview) and automated mechanisms that detect and respond to cluster infrastructure and Apache Kafka software issues support all clusters deployed across multiple AZs (three is the default). As a result, you don’t have to worry about downtime to your applications if a component fails. When you use Amazon MSK, you don’t need to start, stop, or directly access your Apache ZooKeeper nodes. In addition, it automatically updates your cluster’s software to keep it working at peak efficiency.
- Replication of data
High-availability replication in Amazon MSK is accomplished by multi-AZ repetition. Therefore, no additional fees are required for data replication.
- Access to a private network
Amazon MSK manages your Apache Kafka clusters in an Amazon Virtual Private Cloud (VPC). Your clusters are accessible to your own Amazon VPCs, subnets, and security groups depending on your configuration. Your network settings and IP addresses are entirely in your hands.
- Control of access at the granular level
Free of charge, cluster authentication and API permission can be simplified using IAM roles or user policies. For Apache Kafka, you no longer need to create and run one-off access management systems. By default, your clusters are protected with the lowest possible privileges. IAM allows you to control who can perform Apache Kafka operations on a cluster, ensuring that only authorized users can make changes or access data. ACLs in Apache Kafka with Simple Authentication and Security Layer (SASL)/Salted Challenge Response Authentication Mechanism (SCRAM) or mutual Transport Layer Security (TLS) authentication can also be used for provisioned clusters to limit client access to resources.
- Encryption
Amazon MSK encrypts your data at rest without the need for any additional settings or third-party software. The default AWS Key Management Service (KMS) key or your key can be used to encrypt all data at rest in provisioned clusters. You may also use TLS to encrypt data in transit between brokers and clients on your cluster. Serverless clusters encrypt all data in transit and at rest using service-managed keys and TLS by default.
- Deeply Integrated
AWS integrations in Amazon MSK are unmatched by any other provider. These are some of the integrations:
- Service-level access control for Apache Kafka through AWS IAM.
- Amazon Kinesis Data Analytics for running Apache Flink applications in Apache Kafka to process streaming data.
- Streaming SQL and long-running SQL operations can be conducted with Apache FlinkSQL in Amazon Kinesis Data Analytics Studio.
- Amazon Glue Schema Registry to manage and evolve schemas from a single location.
- Amazon Web Services (AWS) Internet of Things Core (IoT Core) for MSK event streaming
- Capturing and analyzing change data using AWS Database Migration Service (AWS DMS).
- Using Amazon VPC (Virtual Private Cloud) to isolate networks and connect private clients,
- Encryption at rest using the AWS Key Management Service (AWS KMS)
- Mutual TLS client authentication with AWS Certificate Manager Private Certificate Authority
- Secure storing and management of SASL/SCRAM secrets through AWS Secrets Manager
- It is possible to use AWS CloudFormation to create an Amazon MSK instance in code.
- Cluster, broker, topic, consumer, and partition-level metrics can be monitored using Amazon CloudWatch.
- Run Apache Kafka natively.
With Amazon MSK, applications and tools created for Apache Kafka function right out of the box, requiring no application code modifications.
- Access to an easier-to-use version
After Apache Kafka goes public, Amazon MSK normally releases the latest version.
- Seamless upgrades
You may determine whether to take advantage of new features and bug fixes in new Apache Kafka versions by upgrading versions on provided clusters in just a few clicks. Client I/O availability may be maintained for clients using best practices with Amazon MSK’s automated distribution of version upgrades on running clusters. In addition, Amazon MSK automatically upgrades Apache Kafka versions for serverless clusters.
- Affordability
You may get started with Amazon MSK for as little as $2.50 per day. Compared to other managed providers, customers typically pay between $0.05 and $0.07 per GB consumed. To learn more about price, see the Amazon MSK Pricing page.
- Scaling a broker (provisioned clusters only)
In minutes, you may change the size or family of Apache Kafka brokers in your Amazon MSK clusters without any disruption. Scaling Amazon MSK clusters by altering their size or family is a common practice since it allows you to adapt the computing capability of the cluster to changing workloads. Furthermore, because it does not necessitate partition reassignment, which may affect Apache Kafka’s availability, this approach may be preferable.
- Scaling of clusters (serverless clusters only)
In response to your application’s throughput requirements, Amazon MSK automatically scales the resources of your clusters.
- Automatic management of partitions
Cruise Control, a popular open-source tool for Apache Kafka, automatically assigns partitions on your behalf when using Amazon MSK. Using Amazon MSK for serverless clusters, you don’t have to worry about partition assignments.
- Auto-scaling of storage (provisioned clusters only)
As your storage needs change, you can easily increase the storage allocated per broker using the AWS Management Console or the AWS Command Line Interface (AWS CLI). A policy that automatically expands your storage capacity as your streaming needs rise can also be implemented.
- Streaming performance may be easily observed by default using CloudWatch metrics.
Amazon CloudWatch can be used to monitor and analyze crucial data to understand better and maintain the performance of streaming applications. A Prometheus server can export JMX and Node metrics from Open Monitoring (provisioned clusters only). It is possible to monitor Amazon MSK using technologies such as Datadog, Lenses, New Relic, Sumo Logic, or a Prometheus server and convert your existing monitoring dashboards to Amazon MSK using Open Monitoring.
- A Prometheus server can be used to export JMX and Node metrics from Open Monitoring (provisioned clusters only)
It is possible to monitor Amazon MSK using technologies such as Datadog, Lenses, New Relic, and Sumo Logic or a Prometheus server and convert your existing monitoring dashboards to Amazon MSK using Open Monitoring. Open Monitoring with Prometheus is available in the documentation section.
Amazon MSK Connect
Use AWS to execute Apache Kafka Connect workloads with Amazon MSK Connect, a part of the AWS MSK platform. Connectors that transport data between Apache Kafka clusters and external systems like databases, file systems, and search indexes may be easily deployed, monitored and automatically scaled with this capability. In addition, it is possible to move your Kafka Connect applications over to MSK Connect without having to make any modifications to the code. If you use MSK Connect, there is no requirement for a cluster infrastructure.
Benefits
- Managed
There is no need to set up infrastructure or Apache Kafka Connect clusters with MSK Connect. Instead, the service manages clusters, workers, and connectors. So you can focus on developing your streaming data flows to and from Apache Kafka clusters, not on infrastructure monitoring and patching.
- Automatic scales
Data flows fluctuate, with varying volumes coming from various sources. MSK Connect is serverless and scales workers as needed, so you only pay for what you use to transport data to and from your Apache Kafka cluster.
- Connectors run
MSK Connect works with Apache Kafka Connect. So you may run any connector compatible with Apache Kafka Connect 2.7.1 and up, whether it was developed by one of our partners, the open-source community, or your own company. In addition, MSK Connect lets you run third-party connector plugins on AWS.

Download list of all AWS Services PDF
Download our free PDF list of all AWS services. In this list, you will get all of the AWS services in a PDF file that contains descriptions and links on how to get started.
Amazon MSK Serverless
It is possible to operate Apache Kafka on Amazon MSK Serverless without the need to manage and scale the cluster’s capacity. Instead, Apache Kafka can be used on-demand thanks to MSK Serverless, which automatically provisions and scales CPU and storage resources.
Benefits
- Stream data easier
MSK Serverless automatically controls cluster capacity and Apache Kafka partitions. In just a few clicks, and MSK Serverless cluster may be created.
- Insta-scale
MSK Managing cluster capacity or reassigning Apache Kafka partitions isn’t necessary with Serverless.
- Cost-effective
MSK Serverless uses throughput-based pricing, so you only pay for data you stream and retain, not idle brokers or storage.
Need help on AWS?
AWS Partners, such as AllCode, are trusted and recommended by Amazon Web Services to help you deliver with confidence. AllCode employs the same mission-critical best practices and services that power Amazon’s monstrous ecommerce platform.
Amazon MSK Pricing
The cost of using Amazon Managed Streaming for Apache Kafka (MSK) is based on how often you utilize it. There are no minimum costs or upfront commitments. You will not be charged for the Apache ZooKeeper nodes that Amazon MSK provides for you, nor will you be charged for data transfer between brokers or between Apache ZooKeeper nodes and brokers inside your clusters, as long as you use Amazon MSK.
It is determined by the type of resource you create that Amazon MSK will charge you for. Clusters can be divided into MSK clusters and MSK Serverless clusters. MSK clusters allow you to set and scale cluster capacity to match your requirements. With MSK Serverless clusters, there is no need to specify or scale the capacity available. You can also create Kafka Connect connectors using MSK Connect.
Pricing Components for Amazon MSK
- Every Apache Kafka broker instance: Each broker instance in your MSK cluster incurs a cost.
- The amount of storage you provide in your cluster: Storage capacity within your cluster is a significant cost factor.
- MSK Serverless charges: You are billed for cluster, partition, and storage when using MSK Serverless.
- MSK Connect: Charges are based on each Kafka Connect worker’s number and size (MCUs).
")
Text AWS to (415) 890-6431
Text us and join the 700+ developers that have chosen to opt-in to receive the latest AWS insights directly to their phone. Don’t worry, we’ll only text you 1-2 times a month and won’t send you any promotional campaigns - just great content!
Related Articles

Building a Customer Support Resolution Agent with Claude
A practitioner’s guide to Scenario 1 of the Claude Certified Architect exam — agentic loops, MCP tool design, escalation logic, and the tradeoffs that separate production systems from demos.
Building an AI-Powered Communication Hub
Your customers reach out through SMS. Through email. Through WhatsApp. Through web chat.
Your team responds through… spreadsheets? Disconnected inboxes? Maybe a CRM that sort of ties things together?
Meanwhile, each channel has its own queue, its own response time, its own tribal knowledge about how to handle common questions. Customer context gets lost between channels. Response quality varies wildly depending on who’s working.
There’s a better way. Amazon Bedrock—combined with AWS End User Messaging and SES—enables enterprises to build unified communication hubs where AI handles routine inquiries across every channel, escalates complex issues to humans, and maintains full context throughout the customer journey.
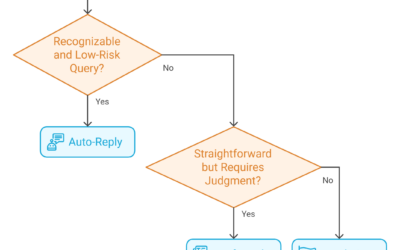
Automating Email Triage with Generative AI
Your team processes hundreds—maybe thousands—of emails per day. Each one needs to be read, understood, categorized, and routed to the right person.
That’s a lot of human brainpower spent on triage.
What if AI could handle that categorization in seconds? What if urgent emails automatically escalated, routine inquiries queued for batch processing, and spam silently filtered—all without human intervention?