
How Amazon Athena Works
Amazon Athena simplifies querying data stored in Amazon S3. Users can access it through the AWS Management Console, where they can point Athena to their S3 data and create the necessary schema. This can be achieved by writing DDL (Data Definition Language) statements or using the Athena create table form. Once the schema is in place, users execute SQL queries through the built-in query editor.
What’s remarkable about Amazon Athena is that it automatically provisions the required compute resources to return query results swiftly, often within seconds. There’s no need to load data or undertake complex ETL (Extract, Transform, Load) processes, making it highly efficient for those with SQL skills.
Features
Amazon Athena is a query service that allows you to interact with your data to perform basic SQL analysis on data stored in Amazon S3. Athena allows users to direct it at their S3 data with a few clicks in the AWS Management Console. They can now begin using conventional SQL to conduct interactive queries and obtain responses in seconds. Due to Athena’s serverless nature, users only need to pay for the queries they execute and not for any associated infrastructure. Athena can be used for various log processing, data analysis, and interactive querying tasks. With Athena, scaling is handled automatically, with queries executed in parallel, allowing for quick returns even with big datasets and sophisticated queries.
Amazon Athena proved to be an optimal solution for the client’s data science team due to its ability to effortlessly query vast data sources without the burden of handling servers or data warehouses. The client’s various datasets were consolidated into a centralized S3 bucket, enabling users to access specific data sets stored in Amazon S3 simply by configuring the schema and running queries using Amazon Athena’s integrated query editor or data API. Moreover, the familiarity of the data science team with ANSI SQL queries facilitated a seamless transition to Amazon Athena. The serverless architecture of Amazon Athena paved the way for scalability without the traditional server management constraints, which ultimately led to substantial cost savings in terms of operational expenses for the client.
Serverless with an inexistent support system and no management
Managing infrastructure is unnecessary because Amazon Athena does not have any servers. As your datasets and user base expand, you can focus on developing new applications rather than worrying about your infrastructure. Athena handles this mechanically so you may concentrate on the data rather than the underlying infrastructure.
Easy-to-use
To get started, log into the Athena console, define your schema with the console wizard or DDL statements, and start querying with the built-in editor. AWS Glue can automatically explore data sources to find data and update your Data Catalog with new table and partition definitions. In seconds, results are presented in the console and written to S3. You can also save them. With Athena, you don’t require sophisticated ETL jobs to analyze data. Anyone with SQL expertise can evaluate massive datasets fast.
Need help on AWS?
AWS Partners, such as AllCode, are trusted and recommended by Amazon Web Services to help you deliver with confidence. AllCode employs the same mission-critical best practices and services that power Amazon’s monstrous ecommerce platform.
Use regular SQL to query
Amazon Athena leverages Presto, a low-latency, interactive SQL query engine. You can perform ANSI SQL queries against big Amazon S3 datasets with support for massive joins, window functions, and arrays. Athena supports CSV, JSON, ORC, Avro, and Parquet. With Athena’s federated data source connectors, you may query and join data from Amazon S3. Athena’s JDBC and ODBC drivers let you perform queries via the console, API, CLI, and AWS SDK, and support BI and SQL development apps.
Pay per query
With Amazon Athena, you pay just for queries. You’re charged based on the amount of data scanned by each query. You can save money and improve speed by compressing, splitting, or transforming your data to a columnar format. Each of these processes minimizes the amount of data Athena has to scan to run a query.

Download our free PDF list of all AWS services. In this list, you will get all of the AWS services in a PDF file that contains descriptions and links on how to get started.
Quick speed
Thanks to Amazon Athena, the quick performance you need doesn’t necessitate any expertise in cluster management or tweaking. Athena’s integration with Amazon S3 is intended for speed. Athena automatically parallelizes query execution, allowing for rapid response times even on massive datasets.
High availability and long life span
Because of its high availability, Amazon Athena performs queries using compute resources from many data centers, automatically rerouting them if necessary. Your data is very accessible and durable because Athena uses Amazon S3 as its underlying data store. Amazon Simple Storage Service (S3) is a reliable data storage service with an object durability design of 99.999999999%. Your information is saved in various locations, and at each location, it is stored on multiple devices.
Secure
Through the use of AWS Identity and Access Management (IAM) policies, access control lists (ACLs), and Amazon S3 bucket policies, you may restrict who has access to your data in Amazon Athena. If you utilize IAM policies, you can give specific permissions to users for your S3 buckets. Data in S3 can be protected from Athena queries by limiting access to specific users. Athena makes it simple to query encrypted Amazon S3 data and save the decrypted results back to the same bucket. It is possible to encrypt data either on the server or on the client’s end.
Integrated
Amazon Athena is preconfigured to seamlessly integrate with AWS Glue, providing robust support for Extract, Transform, and Load (ETL) operations. With Glue Data Catalog, you can consolidate metadata across multiple services, enabling a centralized and comprehensive view of your data assets. By utilizing Glue’s crawling capabilities, you can effortlessly discover new data sources, automatically populating your Data Catalog with up-to-date table and partition definitions. This ensures that your metadata remains accurate and relevant.
AWS Glue is a fully managed extract, transform, and load (ETL) service that offers robust support for data integration. Glue provides a centralized and comprehensive view of data assets by consolidating metadata across multiple services. It simplifies the discovery of new data sources by automatically populating the Data Catalog with up-to-date table and partition definitions. Glue’s ETL features also enable users to transform data or convert it into columnar formats, optimizing query performance and reducing costs. It also supports connectors for ordinary third-party data stores, allowing for the analysis of disparate data sets without manual data movement or transformation.
Glue’s fully managed ETL features empower you to effortlessly transform your data or convert it into columnar formats, optimizing query performance and driving down costs. With Glue’s ETL engine, you can generate Scala or Python code to customize and tailor your data transformation processes according to your specific requirements. This flexibility allows for an efficient and tailored ETL workflow.
While Amazon Athena focuses on query analysis and interactive querying using SQL, AWS Glue focuses on data integration, metadata management, and ETL processes. This difference in focus makes them suitable for different use cases. Athena excels in real-time data analysis, log analysis, and clickstream events, while Glue is designed for managing structured, semi-structured, and unstructured data formats. Both services seamlessly integrate with Amazon S3, simplifying the data analysis workflow and providing efficient and scalable solutions for working with data stored in S3.
Distributed query
Connectors for common third-party data stores including MySQL, PostgreSQL, and Redis are supported by Athena, along with Amazon DynamoDB, Amazon Redshift, Amazon OpenSearch, and many more. Athena’s data connectors make it possible to draw conclusions from disparate data sets without having to manually move or transform the data using ETL scripts. You can extend SQL queries to hundreds of users when you run them as AWS Lambda functions and offer cross-account access using data connectors.
Amazon Redshift is a fully managed data warehousing service that allows you to analyze large datasets using SQL queries. Redshift can directly query data stored in Amazon S3, allowing you to leverage the power and scalability of Redshift while keeping your data in S3. This allows you to perform complex analytical queries on large datasets without having to load the data into Redshift first.
A notable feature of Redshift is Redshift Spectrum, which enables you to run queries that span both the data stored in Redshift and the data stored in S3. This gives you even more flexibility in your analysis, as you can seamlessly access and analyze data from both sources in a single query.
Both Amazon Athena and Amazon Redshift provide seamless integration with Amazon S3, allowing you to easily analyze and query data stored in S3 without the need for complex data loading or transformation processes. This simplifies the data analysis workflow and provides users with efficient and scalable solutions for working with their Amazon S3 data sets.
As a serverless service, Amazon Athena offers the advantage of not requiring any additional infrastructure to scale, manage, and build data sets. Running directly over Amazon S3 data sets, Athena functions as a read-only service, ensuring that the original S3 data sources remain untouched. It supports various data formats, including structured, semi-structured, and unstructured data, making it a versatile choice for ad-hoc queries using Presto and ANSI SQL.
In contrast, AWS Redshift is a powerful petabyte-scale data warehouse service based on PostgreSQL. While it also integrates seamlessly with Amazon S3, Redshift operates differently. It requires users to load data into the service and create tables before running queries. Redshift ensures efficient query processing for large structured data sets by utilizing clusters. This makes Redshift suitable for real-time data analysis, clickstream events, and log analysis, where fast query results are crucial.
It’s important to note that while both services offer integration with Amazon S3, AWS Redshift is generally faster than Amazon Athena in generating query results. However, this increased performance comes with a cost, as Redshift charges for both compute and storage usage.
Learning by machine (ML)
With an Athena SQL query, you may conduct inference using a model you created in SageMaker Machine Learning. The use of ML models into SQL queries simplifies previously difficult operations like anomaly detection, customer cohort analysis, and sales forecasting. All one needs is some familiarity with SQL queries in order to use Athena to execute machine learning models hosted on Amazon SageMaker.
General Use Cases
Amazon Athena provides a solution for executing ad-hoc queries on data sets stored in Amazon S3 using Presto and ANSI SQL. It is especially useful for situations where you need to work with structured, semi-structured, and unstructured data formats. With Athena, you can analyze your data in real-time, making it ideal for scenarios such as real-time data analysis, clickstream events, and log analysis.
Additionally, Amazon Athena offers a wide range of use cases to cater to diverse data analytics needs. These include running ad-hoc analytics on big data, providing a cost-effective alternative to Redshift for complex operations, checking new datasets for validity, performing streaming analytics, querying encrypted data, creating a unified metadata repository, analyzing data spread across multiple data stores, designing self-service ETL pipelines, integrating with AWS Step Functions, unifying data sources for ML training workflows, and developing user-facing data applications. This versatility makes Amazon Athena a powerful tool for handling a variety of data analytics tasks efficiently and effectively.
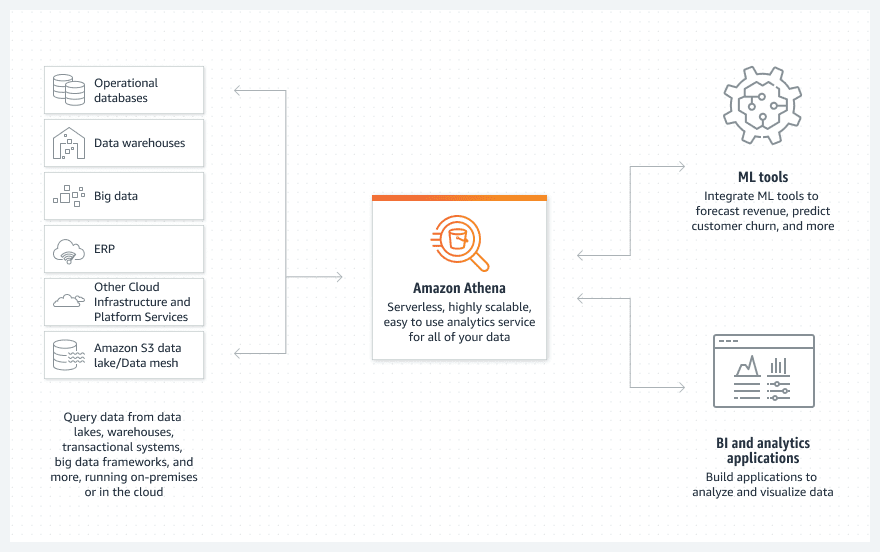
Advantages
Instant querying
Athena is an ETL that doesn’t require a server. You can run queries on your data fast without needing to manage servers or data storage facilities. Simply connect to your Amazon S3 data, define the schema, and begin querying with the integrated query editor. You can access all of your S3 data with Amazon Athena, and there’s no need to put up any elaborate procedures to extract, transform, and load the data (ETL).
Get charged per search
Data scanning is an add-on service.
Pricing for Amazon Athena SQL Queries follows a unique structure that is decoupled from the number of queries you send. The cost is determined by the amount of data your queries scan, with a fixed fee of $5 per terabyte. The advantage lies in optimizing your data storage to reduce expenses and enhance performance. By employing techniques such as compression, splitting, and organizing data into columnar formats, you can save anywhere from 30% to 90% on per-query costs.
It’s important to note that Athena directly conducts queries on Amazon S3 files, and the storage plan for S3 incurs no additional fees. This means that you have the freedom to utilize the vast storage capabilities of S3 without worrying about any extra charges.
However, Amazon Athena offers Provisioned Capacity for those seeking more control and predictable performance. With this feature, you can allocate specific resources to your queries, allowing for more consistent performance. The pricing for Provisioned Capacity starts at $0.30 per DPU hour, calculated per minute. DPUs, which stand for Data Processing Units, determine the combination of resources required to execute your queries. Each DPU consists of 4 virtual CPUs and 16 GB of memory.
Fully accessible, very effective, and universally accepted
Built on Presto and supporting ANSI SQL, Amazon Athena can read and write to common file formats such as CSV, JSON, ORC, Avro, and Parquet. This versatility enables you to work with different data formats and perform complex analysis, including massive joins, window functions, and arrays. It also facilitates interactive querying, ensuring a seamless and efficient data exploration experience.
Incredibly fast
Despite the size of the data set, the performance remains interactive.
You can rest assured that Amazon Athena will provide you with the computational resources you need for quick, interactive query performance. Because Amazon Athena processes queries in parallel automatically, you may expect to receive the most results in a matter of seconds.
Pricing
When comparing the pricing of Amazon Athena and Microsoft SQL Server, there are notable differences. Amazon Athena has a starting price of $5 per TB of data scanned. On the other hand, Microsoft SQL Server offers a free option called Express edition. However, for the Enterprise SQL Server 2022, the cost can go up to $15,123. Therefore, while Amazon Athena has a fixed pricing model based on data scanned, Microsoft SQL Server has various editions with different associated costs, ranging from free to a significantly higher price. These techniques can potentially save between 30% to 90% on per-query expenses.
It is important to note that Athena directly queries Amazon S3 files, eliminating the need for additional storage fees. This means that the S3 storage plan is free of any extra charges. This approach not only simplifies the pricing structure but also allows for seamless integration with your existing S3 data.
Limitations
Optimization limitations
Athena’s optimization is limited to queries only. Data that is already stored in Amazon S3 cannot be optimized, including the underlying data. Even when attempting to transform Amazon S3 data with AWS Glue, caution must be taken to avoid negatively impacting other services accessing the same data.
Shared resources
According to Amazon’s Service Level Agreement (SLA), all AWS Athena users worldwide share the same resources when running their queries. This multi-tenancy approach can occasionally lead to resource strain, resulting in fluctuating query performance.
Lack of data manipulation operations
Athena is primarily a query service and lacks a built-in Data Manipulation Language (DML) interface for tasks such as inserting, deleting, and updating data.
Absence of indexing options
Athena does not offer indexing options, which can potentially increase its operational load and impact overall performance, especially when dealing with large tables.
Partitioning requirements
Efficient queries in Athena require data partitioning and managing the partitions to meet performance requirements. For example, scanning every 500 partitions will increase querying time by a second.
Partitioning data helps Athena to limit the amount of data scanned during each query, which in turn enhances performance and reduces costs. Once partitioned, managing these partitions effectively becomes crucial.
Limited support for additional features
Athena does not support Presto federated connectors, stored procedures, parameterized queries, functions like CREATE TABLE LIKE, EXECUTE ? USING, DESCRIBE INPUT, DESCRIBE OUTPUT, MERGE, and UPDATE. To connect data sources, you need to use Amazon Athena Federated Query.
Timeouts
In cases where a table contains thousands of partitions, an Athena query can timeout.
Treatment of hidden files
Athena considers source files starting with a dot or underscore as hidden files.
Maximum row and column size
The maximum size for a row or column in Athena is limited to 32 megabytes.
Limited support for certain S3 storage classes
Athena does not support querying data in S3 Glacier and S3 Glacier Deep Archive storage classes.