
Data lake vs data warehouse
Processing raw data involves several challenges and investments. Firstly, it is crucial to invest significantly in the right skills and experience. Professionals with expertise in data processing techniques and tools are needed to handle and manipulate the data effectively.
A deep understanding of the best use cases for each data storage technology is essential. Different data storage solutions, such as databases, data lakes, or data warehouses, offer distinct advantages and limitations. Determining the most suitable technology for the specific data processing requirements is important. Investments in infrastructure and technology are also necessary. Reliable and scalable hardware and software infrastructure must be in place to efficiently process large volumes of raw data. This may include powerful servers, storage systems, and data processing tools or frameworks.
Information is the indispensable asset used to make critical decisions about your organization’s future. This is why choosing the right model requires thoroughly examining the core characteristics inherent in data storage systems.
Two main types of repositories are available, each with diverse use cases depending on the business scenario. Although each primary purpose is to store information, their unique functionalities should guide your choice—or maybe you want to use both!
What is the difference? In short, data warehouses are intended for examining structured, filtered data, while data lakes store raw, unfiltered data of diverse structures and sets.
In this article, we examine the lakes and warehouses for storing information. After explaining them, we compare and contrast them and tell you where to start. Consult the table of contents to find a section of particular interest.
Table of Contents
What is a data lake?
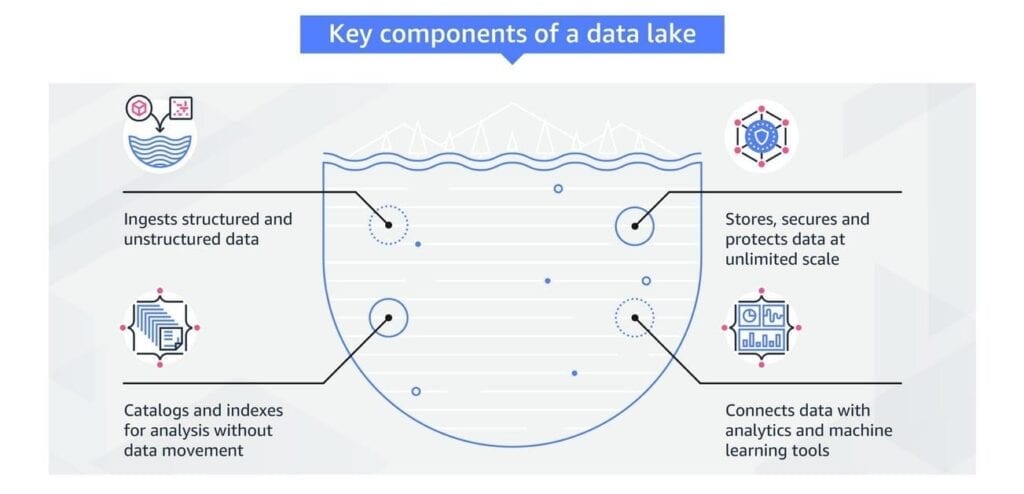
A data lake contains big data from various sources in an untreated, natural format, typically object blobs or files. This centralized repository enables diverse data sets to store flexible information structures for future use in large volumes.
A data lake is a centralized and highly scalable repository that is designed to store raw and unprocessed data from various sources. Unlike traditional data storage systems, a data lake allows users to store data in its original format without requiring any predefined structure or schema. The purpose of a data lake is to enable organizations to perform different types of analysis on this raw data, resulting in valuable insights that can drive improved decision-making.
Building a data lake involves a series of manual steps, making the process complex and time-consuming. Initially, data from diverse sources must be loaded into the data lake, ensuring the data flows are monitored effectively. The data may also need to be partitioned for efficient querying and analysis. Security measures such as encryption must be set up, and appropriate key management strategies must be implemented. Another important aspect of building a data lake is dedicating redundant data to optimize storage and improve data quality.
However, simply creating a data lake without considering the right technology, architecture, data quality, and data governance can result in what is known as a “data swamp.” This refers to a situation where the data lake becomes an isolated pool of cumbersome, difficult-to-use, and hard-to-understand data inaccessible to users.
Data Lake architecture works by integrating various tools, services, and techniques to efficiently manage data ingestion, storage, retrieval, analysis, and transformation processes. In a Data Lake architecture, data is stored in a format incorporating diverse data types and sources to derive valuable business insights.
Key components of a typical Data Lake architecture include:
- Resource manager: Responsible for allocating appropriate resources for different tasks within the Data Lake.
- ELT (Extract, Load, Transform): This process involves extracting data from various sources, loading it into the Data Lake’s raw zone, and then cleansing and transforming it for analysis.
- Connectors: Enable users to easily access and share data in preferred formats through various workflows.
- Data classification: This function supports functions such as profiling, cataloging, and archiving, allowing teams to track changes in data content, quality, history, storage location, and more.
- Analytics service: This service should be fast, scalable, and distributed to support different data workloads in multiple languages.
- Data security: Ensures data protection through masking, auditing, encryption, and access control, whether the data is at rest or in transit.
What is a data warehouse?
A data warehouse is a centralized repository of integrated data that, when examined, can serve for well-informed, vital decisions. Data flows from transactional systems, relational databases, and other sources where they’re cleansed and verified before entering the data warehouse.
Data analysts can access this information through business intelligence tools, SQL clients, and other diagnostic applications. Many business departments rely on reports, dashboards, and analytics tools to make day-to-day organizational decisions.
Extract, transform, load (ETL) and extract load, transform (E-LT) are the primary approaches to build a data warehouse.
Data lake vs data warehouse: key differentiators
| Characteristics | Data Warehouse | Data Lake |
|---|---|---|
| Content | Relational from transactional, operational databases, and line of business applications | Non-relational and relational from IoT devices, web sites, mobile apps, social media, and corporate applications |
| Schema | Designed prior to data warehouse implementation (schema-on-write) | Written on the time of analysis (schema-on-read) |
| Performance/Price | Fastest query results in using a higher cost storage | Query results getting faster using low-cost storage |
| Quality | Curated data that serves as the primary source of information | Any data - structured or unstructured |
| Users | Business analysts | Data scientists, big data engineers, and business analysts (when using structured data) |
| Analytics | Batch reporting, BI and visualizations | Machine Learning, predictive analytics, data discovery, and profiling |
Data lake vs data warehouse: why do I need them?
Businesses that leverage data to make informed decisions invariably outperform their competition.
Why?
Because their business decisions are rational and based on accurate statistics, if you excel in a particular area, you should concentrate on that sector. You can’t decide where to dedicate your resources when you cannot locate the corresponding data!
Smartly processed information will help you identify and act on areas of opportunity. When applied by diligent experts such as AllCode, it attracts and retains customers, boosts productivity, and leads to data-based decisions.
A survey performed by Aberdeen shows that businesses with data lake integrations outperformed industry-similar companies by 9% in organic revenue growth.
Data lake vs. data warehouse: coordinated
Organizations often require both options, depending on their needs and use cases; this synchronization is easily achievable with Amazon Redshift.
The contents of a data warehouse must be stored in a tabular format for SQL to query the data. However, not all applications require that data be in a tabular form. Applications like big data analytics, full-text search, and machine learning can access partially structured or entirely unstructured data with data lakes.
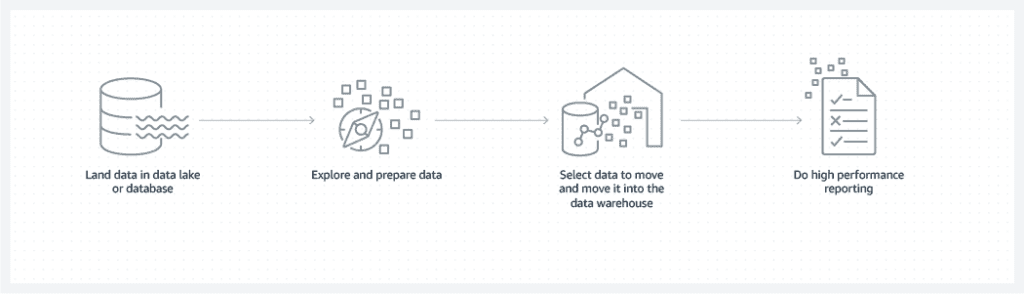
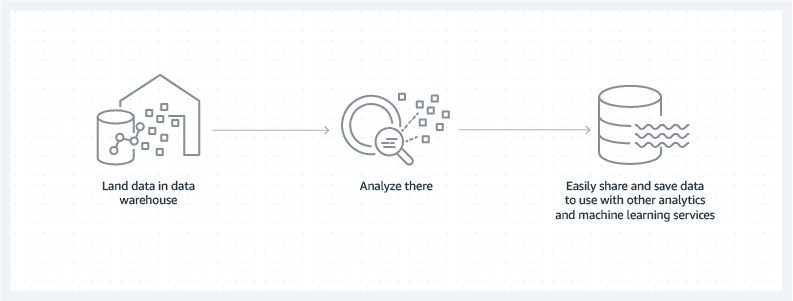
As the volume and variety of your data expands, you might explore using both repositories. Follow one or more common patterns for managing your data across your database, data lake, and data warehouse. See a few options below:
Data lake vs data warehouse: which is best for me?
Before you choose which option favors your business, consider the following questions. Then, look at some of the industries we have described to see which align with yours.
What type of data are you working with?
You should probably opt for a data lake if you’re working with raw, unstructured data continuously generated in significant volumes. However, remember that data lakes can surpass the practical needs of companies that don’t capture significant, vast data sets.
A data warehouse is the way to go if you derive data from a CRM or HR system containing traditional, tabular information.
What are you doing with your data?
Data lakes provide extraordinary flexibility for putting your data to use. They also allow you to store instantly and worry about structuring later. If you don’t need the data right away but want to track and record the information, data lakes will do the trick.
A data warehouse will likely speed up the process if you’re only going to generate a few predefined reports.
What can your organization afford?
Considerations for architecting cost-optimized data storage involve understanding the differences between data warehouses and data lakes and evaluating an organization’s specific needs and capabilities.
Data warehouses serve as large-scale repositories for various structured data types, making identifying patterns and insights through data analysis easy. However, building and maintaining a data warehouse requires a significant investment, including specialized skills and experience.
By comparison, data lakes are suitable for organizations with data specialists who can handle data mining and analysis. They are particularly beneficial for automating pattern identification using advanced technologies like machine learning and artificial intelligence. Data lakes also function as scalable online archives, allowing organizations to store vast amounts of data that may not require immediate transformation or analysis.
Organizations should consider the resources required for each data storage technology when evaluating cost savings. Data warehouses require substantial investments in skills, experience, and an understanding of specific use cases. On the other hand, data lakes can provide cost savings by eliminating the need for immediate data transformation and analysis.
What tools exist in your organization?
Maintaining a data lake isn’t the same as working with a traditional database. It requires engineers who are knowledgeable and practiced in big data. If somebody within your organization is equipped with the skillset, take the data lake plunge.
However, if big data engineers aren’t included in your company’s framework or budget, you’re better off with a data warehouse.
Healthcare Industry
The healthcare industry requires real-time insights to attend to patients with prompt precision. Hospitals are awash in unstructured data (notes, clinical data, etc.) that require timely submission. Data lakes can quickly gather this information and record it to be readily accessible.
Education Systems
Big data in education has been in high demand recently. Information about grades, attendance, and other aspects is raw and unstructured, flourishing in a data lake.
Financial Services
Information is generally structured and immediately documented in financial institutions. Since this data needs to be accessed company-wide, a data warehouse is indicated for easier access.
Transportation Field
In the transportation industry, specifically supply chain management, you must be able to make informed decisions in minutes. Data lakes provide access to quick and flexible data at a low cost.
Data lake on AWS
AWS has an extensive portfolio of product offerings for its data lake and warehouse solutions, including Kinesis, Kinesis Firehose, Snowball, Streams, and Direct Connect, which enable users to transfer large quantities of data into S3 directly. Amazon S3 is at the core of the solution, providing object storage for structured and unstructured data—the storage service of choice to build a data lake.
Lake Formation offers a range of capabilities that effectively handle data preparation and cleaning tasks. One of its noteworthy features is the utilization of machine learning (ML) techniques to enhance data consistency and quality. Lake Formation can efficiently clean and deduplicate data using ML algorithms, improving its quality.
Another essential capability provided by Lake Formation is the ability to reformat data, making it suitable for various analytics tools such as Apache Parquet and Optimized Row Columnar (ORC). This ensures the data is correctly structured and optimized for efficient analysis and processing.
Lake Formation incorporates an ML-powered transform known as FindMatches. This transformative tool enables users to match records present in different datasets, facilitating the identification and removal of duplicate records. The process is exceptionally streamlined, typically requiring minimal human intervention, improving data integrity and accuracy.
With Amazon S3, you can efficiently scale your data repositories in a secure environment. Leveraging S3, you can use native AWS services to run big data analytics, artificial intelligence (AI), machine learning (ML), high-performance computing (HPC), and media data processing applications to gain an inside look at your unstructured data sets.
Start your data lake formation by visiting here:
http://aws.amazon.com/blogs/big-data/getting-started-with-aws-lake-formation/
Data warehouse on AWS
AWS is also a hub for all of your data warehousing needs. Amazon Redshift provides harmonious data warehouse deployment in just minutes and integrates seamlessly with your existing business intelligence tools.
To get started with data warehousing on AWS, visit here: http://aws.amazon.com/getting-started/hands-on/deploy-data-warehouse/
Data lake vs data warehouse partner
Transforming data into a valuable asset of utility to your organization is a complex skill that requires an array of tools, technologies, and environments. AWS provides a broad and deep arrangement of managed services for data lakes and data warehouses. Data lakes and data warehouses are not direct competitors but instead work together in a complementary manner to enhance data management and analytics capabilities. Utilizing a data lake as a central repository for raw and unstructured data, organizations can store large volumes of diverse data without a predefined structure.
This empowers data warehouses to efficiently query and analyze structured and processed data. The data lake acts as a staging area, allowing data engineers and data scientists to explore, clean, and transform the data before loading it into the data warehouse. By carefully selecting the best data lake solution along with a top data warehouse solution, organizations can maximize the value and usability of their data. AWS managed services for data lakes and data warehouses, combined with the expertise of APN Consulting Partners in designing and implementing these solutions, ensure that your business is equipped with the most suitable technologies for effective data management and analytics. This comprehensive approach enables organizations to make informed decisions and derive actionable insights from their data.